PS(FEI)
Obsah
- 1 1. přednáška, Klasické architektury počítačů, Intelx86, AMD64, ARM
- 2 1. cvičení
- 3 2. přednáška, Paralelní výpočty, Amdahlův zákon
- 4 2. cvičení
- 5 3. přednáška - Výpočetní clustery
- 6 3. cvičení
- 7 4. přednáška - Masivní paralelizace s použitím grafických karet
- 8 4. cvičení
- 9 5. přednáška - Přednáška o Superpočítačích a exkurze v ostravském superpočítači
- 10 6. přednáška - Procesory ARM jako platforma pro řízení a sběr dat
- 11 7. přednáška - Procesory ARM a sběrnice SPI, I²C, UART a další
1. přednáška, Klasické architektury počítačů, Intelx86, AMD64, ARM
Teoretické základy:
- Mooreův zákon, Gordom Moor(1965), zakladatel firmy Intel, „Počet tranzistorů, které mohou být umístěny na integrovaný obvod se při zachování stejné ceny zhruba každých 18 měsíců zdvojnásobí.“
Původní článek: http://www.monolithic3d.com/uploads/6/0/5/5/6055488/gordon_moore_1965_article.pdf
Současné znění Moorova zákona je že dojde ke zdvojnásobení výkonu/efektivity každých 18 měsíců.
* Na jednom veletrhu automobilů prohlásil Bill Gates:" Kdyby General Motors držel krok s technickým pokrokem jako Microsoft, jezdili bychom v autech za 25$ a na 1 galon benzínu ujeli 1000 mil." * GM hbitě vytvořil odpověď: Kdyby GM vyvinula stejnou technologii, jako Microsoft, jezdili bychom v autech s následujícími vlastnostmi: ** 2x za den by auto mělo poruchu bez zjevného důvodu. ** Při každém překreslení čar na silnici by bylo nutné si koupit nové auto. ** Příležitostně by se auto na dálnici zastavilo. To by se všeobecně respektovalo, znovu by se nastartovalo a jelo dál. ** U jistých manévrů(levá zatáčka) by se auto zastavilo a pomohla by jen demontáž a následná montáž nového motoru. ** Auto by byla jen pro jednu osobu s výjimkou Auto95 a AutoNT, kde by se však za každé další sedadlo platilo zvlášť. ** MacIntosh by vyráběl auta na sluneční energii, jezdila by 5x rychleji a byla by o polovinu lehčí , fungovala by ale jen na 5% silnic. ** Kontrolka tlaku oleje, teploty motoru apod. by nahradila obecná auto-chyba. ** Airbag by se ptal:" Jste si jist...", než by se uvedl v činnost. ** Čas od času by se nedalo auto odemknout. Pomohl by následující trik:zároveň tisknout kliku, otáčet klíčem a rukou se dotýkat antény. ** GM by zákazníky nutila koupit si i s autem sadu deLuxe od společnosti McNally (dceřinná společnost GM), jinak by auto jezdilo alespoň 2x pomaleji. ** Po koupi nového auta by se každý musel znova učit řídit, protože každý nový typ auta by byl jiný. ** Motor by se vypínal tlačítkem "START".
- Turingův stroj (1936)
Od výpočetní síly Turingova stroje se odvozuje turingovská úplnost: turingovsky úplné jsou právě ty programovací jazyky nebo počítače, které mají stejnou výpočetní sílu jako Turingův stroj.
- Harvardská architektura je počítačová architektura, která fyzicky odděluje paměť programu a dat a jejich spojovací obvody. Název pochází z počítače Harvard Mark I, který byl postaven na této architektuře.
- Von Neumannova architektura je v informatice označení pro jednoduché schéma programovatelného počítače, které používá jednu sběrnici, na kterou jsou připojeny všechny aktivní prvky (procesor, paměť, vstupy a výstupy).
Generace počítačů:
1) Sálové počítače (mainframe)
- Nultá generace (využit mechanický princip paměti)
- Z1, 1933, první elektromechanický sálový PC, neměl možnost podmíněných skoků
- Z2,Z3, 1941, zdokonalená verze Z1, neměl možnost podmíněných skoků, používal se na výpočty balistiky rakety V2 (v roce 1998 prokázáno, že je Turing.úplný)
- ABC, 1939, řešení lin rovnic
- Colossus, 1943, dešifrování německých šifer, poprvé použity elektronky
- Mark I, 1944, 4kW, výpočet bal. křivek
- Mark II, 1947
- První generace (plné využití elektronek)
- ENIAC a MANIAC, 1945, výpočty jaderné bomby
- Druhá generace (využití tranzistorů)
- UNIVAC (elektronkový), 1951, první komerčně vyráběný
- Třetí generace (integrované obvody)
- IBM System 360, 1965
- Čtvrtá generace (osobní počítače)
2) Osobní počítače
- 1971 – Intel 4004 – první mikroprocesor – 4bitový
- 1972 – Intel 8008 – 8bitový mikroprocesor
- 1974 – Intel 8080 – 8bitový mikroprocesor, který se stal základem prvních 8bitových osobních počítačů
- 1975 – MOS Technology 6502 – 8bitový mikroprocesor, montovány do Apple II, Commodore 64 a Atari
- 1975 – Motorola 6800 – první procesor firmy Motorola
- 1975 – AMD nastupuje na trh s řadou Am2900
- 1976 – TI TMS 9900 – 16bitový mikroprocesor
- 1976 – Zilog Z80 – 8bitový mikroprocesor, s rozšířenou instrukční sadou Intel 8080, frekvence až 10 MHz
- 1978 – Intel 8086 – 16bitový mikroprocesor, první z architektury x86
- 1978 – Intel 8088 – 16bitový mikroprocesor s 8bitovou sběrnicí, který byl použit v prvním IBM PC v roce 1981
- 1979 – Motorola 68000 – 32/16bitový mikroprocesor
- 1979 – Zilog Z8000 – 16bitový mikroprocesor
- 1980 – IBM 801 – 24bitový experimentální procesor s revoluční RISC architekturou dosahující vynikajícího výkonu
- 1980 – Intel 8051 – 8bitový mikroprocesor se základní sadou periferií pro embedded systémy
- 1982 – Intel 80286 – 16bitový mikroprocesor
- 1983 – TMS32010 – první DSP firmy Texas Instruments
- 1985 – Intel 80386 – 32bitový mikroprocesor (měl 275 000 tranzistorů)
- 1986 – Acorn ARM – 32bitový RISC mikroprocesor, z Advanced RISC Machine, původně Acorn RISC Machine, použit i v domácích počítačích
- 1989 – Intel 80486 – 32bitový mikroprocesor s integrovaným matematickým koprocesorem
- 1989 – Sun SPARC – 32bitový RISC mikroprocesor, z Scalable (původně Sun Processor ARChitecture)
- 1992 – DEC Alpha – 64bitový RISC mikroprocesor
- 1992 – Siemens 80C166 – 16bitový mikroprocesor pro průmyslové embedded systémy s bohatou sadou periferií
- 1993 – Intel Pentium – 32bitový mikroprocesor nové generace (3,3 milionu tranzistorů)
- 1995 – Intel Pentium Pro – 32bitový mikroprocesor nové generace pro servery a pracovní stanice (5,5 milionu tranzistorů)
- 1995 – Sun UltraSPARC – 64bitový RISC mikroprocesor
- 1996 – Intel Pentium MMX 32bitový první se sadou instrukcí MMX pro podporu 2D grafiky
- 1997 – Intel Pentium II – 32bitový mikroprocesor nové generace s novou sadou instrukcí MMX (7,5 milionu tranzistorů)
- 1997 – Sun picoJava – mikroprocesor pro zpracování Java bytekódu
- 1997 – AMD K6-2 – 32bitový první se sadou instrukcí pro podporu 3D grafiky 3DNow!
- 1999 – AMD K6-III – 32bitový poslední procesor do základní desky se super socket 7. Od této chvíle již nemá Intel a AMD procesory do stejného socketu.
- 1999 – Intel Pentium III – 32bitový mikroprocesor nové generace s novou sadou instrukcí SIMD známou jako SSE (9,5 milionu tranzistorů)
- 1999 – Intel Celeron – 32bitový mikroprocesor odvozený původně od Intel Pentium II pro nejlevnější PC
- 2000 – AMD Athlon K75 První procesor s frekvencí 1GHz
- 2000 – Intel Pentium 4 – 32bitový mikroprocesor s řadou technologií orientovaných na dosažení vysoké frekvence
- 2001 – Intel Itanium – 64bitový mikroprocesor nové generace pro servery
- 2001 – AMD Opteron – 64bitový mikroprocesor nové generace pro servery od AMD. Jedná se o historicky nejkvalitnější procesor, jaký kdy AMD vyrobilo.
- 2003 – AMD Athlon 64 – 64bitový mikroprocesor nové generace pro desktopy s instrukční sadou AMD64, zpětně kompatibilní s x86
- 2006 – Intel Core – 64bitová architektura, na které jsou postaveny procesory Core Duo, Core 2 Duo, Core Solo, Core 2 Quad
- 2007 – Společnost AMD uvádí novou řadu procesorů Phenom
- 2008 – Intel Core i7 – nová řada CPU od Intelu pod názvem Nehalem a AMD Phenom II, který staví na 45 nm výrobě
- 2010 – Intel vydává slabší a ořezanější procesory Core i3 a Core i5 postavené na architektuře Nehalem a AMD vydává svůj první šestijádrový procesor Phenom II X6
- 2011 – Intel vydává novou architekturu Sandy Bridge a AMD vydává první procesory s integrovanou grafikou
- 2012 – Intel vydává novou architekturu Ivy Bridge s tzv. "3D" (Tri-Gate) technologií tranzistorů ve 22nm výrobním procesu
- 2013 – Intel vydává architekturu Haswell vycházející z Ivy Bridge, která má velmi znatelně snížit spotřebu
3) Počítač jako služba
- dominující procesory ARM
- vývoj ARM započal v roce 1980, firma se časem vzdala výroby a držela si pouze vývoj a licence
- procesory ARM dnes vyrábí mnoho výrobců, Nvidia, Atmel a další
- výkon ARM procesorů je srovnatelný z procesory Intel, Intel to vedlo k vývoji procesorů Intel Atom
1. cvičení
Seznamte se s programováním v C/C++ v OS linux. Pro překlad využijte řádkový překladač gcc nebo g++. Syntaxe gcc program.c -o program.
Pro práci v Linuxu můžete využít PC v učebnách, vlastní Notebook s nativní instalací Linuxu nebo se můžete prostřednictvím terminálového programu (např.(http://www.putty.org/ Putty])) připojit na server linedu.vsb.cz .
Psaní kódu doporučuji používat některý z jednoduchých editorů jako je mcedit, gedit a jiné. Znalí uživatelé můžou využít editor vim.
Potřebujete-li nápovědu k používaným funkcím krom google využijte také manuálové stránky man 3 printf. Prohlížení se ukončí klávesou q.
Úkol:
Vytvořte program, který jako parametr dostane hash řetězce vytvořený pomocí příkazu md5sum (příklad: echo -n Ahoj | md5hash). Dalším parametrem bude počet znaků řetězce ze kterého se hash vytvořil. Tedy v případě "Ahoj" to bude číslo 4. Program se poté pokusí nalézt původní řetězec ze kterého hash vznikl. Pro měření času po jaký program běžel můžete použít program time. (příklad: time ./mujrogram Ahoj 4). Vyzkoušejte a zapište do grafu časy potřebné k vykonání programu pro různé délky řetězce.
2. přednáška, Paralelní výpočty, Amdahlův zákon
Paralelní výpočty
- vícevláknové
- více procesorové
- více systémové
- homogení
- heterogení
Amdahlův zákon
Amdahlův zákon je pravidlo používané v informatice k vyjádření maximálního předpokládaného zlepšení systému poté, co je vylepšena pouze některá z jeho částí.
Využívá se např. u víceprocesorových systémů k předpovězení teoretického maximálního zrychlení při přidávání dalších procesorů. Zákon je pojmenován po americkém počítačovém architektovi Genu Amdahlovi. Poprvé byl představen na konferenci AFIPS Spring Joint Computer Conference vroce 1967.
Výpočet
Velikost zlepšení můžeme označit jako zrychlení S a bude nám určovat, kolikrát je běh úlohy s vylepšením rychlejší.

nebo také pomocí

Pokud chceme počítat celkový zisk na vylepšení určitých částí, můžeme použít následující postup:
Nejdříve definujeme proměnné
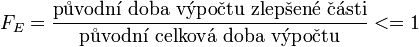

poté můžeme spočítat dobu výpočtu po zlepšení

celkové zrychlení S poté můžeme počítat jako

Příklady
Dílčí zrychlení
Předpokládejme, že výpočet trvá 30 % času, zbytek času je nevyužit či se čeká na I/O. Dále předpokládejme, že výpočet můžeme 5× zrychlit. Jaká bude celková hodnota zrychlení?



Z výpočtu je vidět, že systém bude zrychlen přibližně o 31,6 %.
Paralelizace části výpočtu
Pokud například při výpočtu nějakého problému lze 12 % tohoto výpočtu urychlit paralelním zapojením použitých procesorů (a zbylých 88 % se bude dále řešit sériově), je podle Amdahlova zákona maximální možné zrychlení vylepšené verze (tedy při počtu procesorů blížících se limitně nekonečnu) rovno 1/(1 − 0,12) = 1,136.
Tedy při rozdělení sériová část – paralelní část v poměru 88:12 lze přidáváním dalších procesorů docílit zrychlení jen o 13,6 %.
převzato z www.wikipedia.org
Gustafsonův zákon
Amdahlův zákon zákon počítá s tím, že po paralelizaci se nezmění velikost úlohy, tedy velikost dat. V praxi je to ale často naopak. Po paralelizaci problému se záměrně objem dat zvětší a tím dosáhne za stejnou dobu lepších výsledků. Tyto neduhy odstraňuje Gustafsonův zákon. Ten lze definovat následovně: Předpokládejme, že P označuje počet procesorů a α představuje část problému, kterou není možné paralelizovat (přirozeně sekvenční část problému). Pak maximální zrychlení, kterého je možné docílit, je možné vypočítat jako:

2. cvičení
Úkol: Na základě programu připraveného z minulého cvičení změřte dobu trvání výpočtu paralelní a neparalelní části programu a z naměřených hodnot vypočítejte dle Ambdalova zákona zrychlení prováděného algoritmu. Své výsledky porovnejte s teoretickými předpoklady. Své výsledky vyneste do grafu kde vodorovná osa bude znázorňovat počet procesů použitých při paralelizaci a sviská osa celkové zrychlení procesu (teoreticky vypočtené a prakticky změřené).
Pro měření času běhu programu můžete využít program time. Pro měření doby běhu jednotlivých částí programu můžete použít následující kód:
#include <sys/time.h>
#include <stdio.h>
#include <unistd.h>
int main()
{
struct timeval diff, startTV, endTV;
gettimeofday(&startTV, NULL);
usleep(20000);
sleep(10);
gettimeofday(&endTV, NULL);
timersub(&endTV, &startTV, &diff);
printf("**time taken = %ld %ld\n", diff.tv_sec, diff.tv_usec);
return 0;
}
3. přednáška - Výpočetní clustery
Rozdělení z pohledu způsobu paralelizace
Geograficky rozsáhle distribuované výpočty s centrální správou
Typickým zástupcem může být projekt SETI@Home http://www.seti.org/ . Projekt se zabývá hledáním mimozemských civilizací na základě detekce rádiových signálů. Bohužel dat přijatých radioteleskopy je takové množství, že s detekcí by si neporadily ani dnešní superpočítače. Proto vznikl projekt SETI@Home, kdy program spuštěný na počítači, který je připojený k internetu využívá výpočetní výkon PC v době kdy ho uživatel nepotřebuje. Architektura je následující:
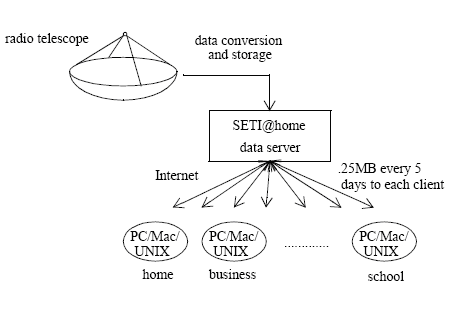
Centrální server shromažďuje data a zasílá je jednotlivým stanicím. Jedná se tedy o výpočetní cluster s centralizovanou správou.
Vizualizace projektu SETI@Home
Firemní výpočetní cluster na úrovni OS bez centrálního prvku
Mezi typické zástupce patří projekt MOSIX a jeho volně šířená varianta OpenMosix. Projekt OpenMosix byl ale již ukončen. V zásadě se jedná o upravené jádro operačního systému Linux, které je schopno programy spuštěné na jednom PC distribuovat na jiná PC. Je tak možné využívat výpočetní výkon několika PC. Velká výhoda tohoto řešení je, že není nutné dělat změny v programech. Stačí v programu použít příkaz fork() a potomci se automaticky budou distribuovat na sousední výpočetní uzly. Řešení není centralizované, tedy každý člen clusteru má stejnou váhu jako jeho kterýkoli jiný.
![]()
Firemní výpočetní cluster s centrálním prvkem
Zástupce tohoto řešení je Windows HPC Server. Základem tohoto řešení je centrální server a výpočetní nody. Jako nody je možné využít specializované servery nebo klasická PC. Propojení těchto nodů je doporučené realizovat pomocí 1GBps LAN případně lepší. Programy psané pro Windows HPC je nutné implementačně přizpůsobit, je tedy nutné programy upravit.
Knihovna pro distribuované výpočty MPI
Jendá se o knihovnu, která se stává standardem pro tvorbu programů využívajících masivní paralelizaci. Velmi pěkný popis se nachází na české wikipedii https://cs.wikipedia.org/wiki/Message_Passing_Interface .
Prostředky IPC a problémy při paralelních výpočtech
Prostředky, které se využívají pro komunikaci mezi procesy se obecně nazývají IPC Inter-Process Communication. Mezi základní prostředky patří:
- Roura
- Sdílená paměť
- Fronta zpráv
- Socket
- Semafor
Příklady použití těchto IPC prostředků najdete na stránkách předmětu Operační systémy. http://poli.cs.vsb.cz/edu/osy/cviceni.html
3. cvičení
- Program pro reverzní hledání hash kláče využívající paralelizmus spusťte v prostředí clusteru MOSIX. Postupně zvyšujte obtížnost výpočtu a pokuste se najít takovou u kteréhé se již vyplatí pracovat v prostředí MOSIX.
- Ověřte které prostředky IPC podporuje cluster MOSIX.
4. přednáška - Masivní paralelizace s použitím grafických karet
Jedním z nejdůležitějších hráčů na poli masivní paralelizace s pomocí grafických karet se stala firma NVidia, která zcela uvolnila programové prostředí pro tvorbu programů pro své grafické karty. Technologir byůa nazvána CUDA z anglického sousloví (Compute Unified Device Architecture).
Obdobnou architekturou disponuje i jeden z největších konkurentů Nvidie a to je ATI, nyní již zcela vlastněná firmou AMD. Existují samozřejmě i jiné technologie jako OpenCL nebo OpenGL, ty jsou ale více určeny pro zpracování obrazu.
Technologie CUDA získala svou oblibu především z důvodů možností obecného použití a to né jen při zpracování obrazu, ale také při vědeckých výpočtech. Známé jsou již implementace neuronových sítí nebo genetických algoritmů využívajících této technologie.

Porovnání výkonu GPU a CPU
Popis CUDA technologie
CUDA podporuje různé jazyky a API, jako Fortran, OpenCL, C nebo DirectX Compute. Zde se omezíme pouze na jazyk C/C++.

CUDA Architektura
Část HW architektury:
- multiprocesory, každý multiprocesor má 8 procesorů
- 32-bitový procesor architektury SIMT (Single Instruction Multi-Thread vycházející z architektury SIMD)
- registry – 32 bitové
- sdílená paměť
- paměť pro konstanty
- globální paměť - paměť určená pro kopírování dat z RAM do GPU a naopak
Architektura programu pro technologii CUDA
Základní rys programů s masivní paralelizací je ten, že se zde v minimální míře vyskytují cykly ve kterých by se procházely datové struktury prvek po prvku. Tyto části programu se nahrazují tak, že program je rozvětven do mnoha vláken přičemž každé vlákno zpracovává část dat, mnohdy pouze jeden prvek pole. Na GPU je možné vytvořit i několik miliónů vláken, které mohou ve velké míře pracovat souběžně.

Architektura paralelizace je reprezentována několika objekty. Jedná se o Grid, Blok a Thread.
- Grid je objekt, který může být až čtyřrozměrný a reprezentuje všechna vlákna.
- Blok je menší objekt, který taktéž může být až čtyřrozměrný, objem bloku je omezen, bloky jsou vždy v celém Gridu stejné
- Thread jedná se o samotné programové vlákno
Při tvorbě programů se používá pojem kernel což je speciální funkce, která je spuštěna v architektuře daného Gridu.
Používá se následující speciální syntaxe:
onecny_nazev_kernelu<<< dim3( 2, 2 ), dim3( 3, 3 )>>>(/*případné parametry*/); // parametry mezi <<< a >>> definují rozměr gridu a bloku
Každý thread má poté k dispozici informace o tom v jaké je pozici v rámci svého bloku a jaká je pozice jeho bloku v rámci gridu. Díky těmto pozicím si může každý thread určit kde se v gridu nachází.
Při psaní programu je nutné si uvědomit, že GPU může adresovat jen ta data, která jsou v paměti grafické karty a proto je nutné data do grafické karty nakopírovat. Slouží k tomu funkce cudaMemcpy. K alokaci paměti na GPU se používá funkce cudaMalloc, obdobně k uvolnění paměti funkce cudaFree.
Pro ptáci na školních PC jsou zpracována následující příklady http://seidl.cs.vsb.cz/download/demo-cuda-ps.tar .
Složitější projekty v příkazovém řádku, pomocí makefile
Pro tvorbu projektů v příkazovém řádku se velmi často využívá Makefile. Pomocí Makefile lze vytvářet i opravdu "gigantické" projekty. Například při kompilaci jádra operačního systému Linux se také používá Makefile. Jedná se vlastně o skript, který spouští dané akce, které jsou zapotřebí pro kompilaci celého projektu. Takže pokud se Váš projekt skládá z dvaceti souborů, které je zapotřebí zkompilovat pro překlad výsledného programu a Vy jeden z těchto souborů upravíte, Makefile zařídí, že se přeloží jen jeden upravený kod a ostatní kody budou zachovány a nebudou se znova kompilovat.
Syntaxe Makefile
cíl: potřebné soubory k dosažení cíle <tab>nástroj jak cíl vytvořit
takže pro příklad jak by mohl Makefile vypadat
vysledny: static.a vysledny.c
gcc vysledny.c static.a -o vysledny
satic.a: prvni.o druhy.o treti.o
ar cr static.a prtni.o druhy.o treti.o
prvni.o: prvni.c
gcc -c prvni.c -o prvni.o
druhy.o: druhy.c
gcc -c druhy.c -o druhy.o
treti.o: treti.c
gcc -c treti.c -o treti.o
4. cvičení
Implementujte algoritmus pro vytvoření MD5 hash, tak aby využíval technologii CUDA. Pro práci použijte server merlin1.cs.vsb.cz . Vytvořte program, který bude využívat technologii CUDA pro zpětné zjištění textu z MD5 hash. Výsledky porovnejte s předchozí implementací na CPU.
5. přednáška - Přednáška o Superpočítačích a exkurze v ostravském superpočítači
Prezentace jsou k dispozici zde:
[Povídání na téma SUPERPOČÍTAČE DNES A ZÍTRA (2009)]
[Povídání na téma SUPERPOČÍTAČE DNES A ZÍTRA (2015)]
6. přednáška - Procesory ARM jako platforma pro řízení a sběr dat
Dominance procesorů ARM se začala projevovat s nástupem "chytrých" mobilních telefonů, kde si tyto procesory postupně získaly dominanci.
Množství vyráběných ARM procesorů začalo strmě růst a důsledkem toho se začala velmi rychle snižovat cena. Vznikl ale jakýsi paradox, že vývoj procesorů zaostával nad dynamikou trhu. Tím se požadavky na nové procesory začaly navyšovat. Množství hromadně vyráběných procesorů ARM bylo někdy takové, že je trh nestihl zkonzumovat, protože se již začaly vyrábět nové výkonnější procesory. Na trhu se tedy objevilo větší množství procesorů ARM pro které nebylo využití.
Výrobci procesorů ARM se tedy snažili najít jiné odbytiště pro své výrobky. Na této vlně se svezl i projekt který započal roku 2011 a pokračuje dosud. V této době se několik profesorů s University of Cambridge rozhodlo podpořit výuku počítačového hardware a vytvořilo miniaturní počítač Raspberry-PI. Projekt se nakonec stal natolik oblíbený, že z původně boční větve v nákupu procesorů ARM se stal směr, který rozhodně nemohl být opovrhován. V současnosti se prodalo již více jak 1mil kusů počítače Raspberry-PI.
Projekty založené na procesorech ARM
Projekt Raspberry-PI

Stručná hostorie Raspberry-PI
- 12.08. 2011, byly přijaty první Alpha desky
- 28.11. 2011, detaily modelu B byly odhaleny
- 10.01, 2012, první sériová výroba
- 19.04. 2012, společnost Farnell začíná Raspberry-PI oficiálně prodávat
- 16.06. 2012, zrušeno omezení na nákup jen jednoho kusu
- 06.09. 2012, výroba přesunuta do továrny Sony ve Velké Británii
- 15.10. 2012, model B je ve verzi s 512MB RAM
- 30.12. 2012, k dispozici model A
- 04.02. 2013, model A je na prodej
- 14.05. 2013, lze zakoupit kameru pro Raspberry-PI
- 03.06. 2013, pro snadnou instalaci OS, zaveden NOOBS
- 28.10. 2013, je k dispozici kamera bez IR čidla
- 07.04. 2014, započata výroba compute-module pro komerční využití
- 14.06. 2014, zahájena výroba modelu B+
- 10.11. 2014, zahájena výroba modelu A+
- 02.02. 2015, zahájena výroba Raspberry PI 2
- 30.04. 2015, uvolněn Windows 10 pro Raspberry-PI
- 08.09. 2015, započata výroba dotykového LCD displaye
Porovnání verzí Raspberry-PI
V následujících odkazech najdete porovnání jednotlivých verzí:
https://opensource.com/life/16/10/which-raspberry-pi-should-you-choose-your-project
https://www.rs-online.com/designspark/raspberry-pi-model-comparison-table
Zajímavé projekty pro Raspberry-PI
https://www.youtube.com/watch?v=blvaYR6aYXA
http://www.wired.com/2012/12/more-raspberry-pi-please/
A mnoho dalších.....
Projekt Banana-PI
http://www.bananapi.org/
![]()

V roce 2013 vznikl konkurenční projekt k projektu Raspberry-Pi. Byl pojmenován Banana-Pi a v době svého vzniku se vyznačoval značně lepšími parametry oproti v té době aktuální verzi Raspberry-PI B+. Tyto rozdíly ale byly smazány po uvedení verze Raspberry-PI B2. Přesto jsou parametry, které projekt Banana-Pi povyšují. Jedná se především o možnost připojení SATA disku a 1GBbps ethernetu. To předurčuje Banana-PI především do role síťového disku.
Porovnání výpočetního výkonu
Porovnání výkonu jednotlivých verzí Banana-Pi a Raspberry-Pi můžete vidět na následující stránce http://www.htpcguides.com/raspberry-pi-vs-pi-2-vs-banana-pi-pro-benchmarks/ .
Projekt Orange-PI
http://www.orangepi.org/


Opět se jedná o projekt, který se snaží "svést na vlně" popularity Raspberry-PI. mezi jeho výhody patří například integrovaná Wif, 1Gbps LAN a podpora mnoha operačních systému jako Linux/Debian, Android a další.
Orange-PI vs. Banana-PI vs. Raspberry-PI
https://www.youtube.com/watch?v=gZNA3k7g42k
Humming Board
HummingBoard je další z variant miniaturních počítačů využívajících procesory ARM. Výrobcem je firma SolidRun, která je již známá svými předchozími miniaturními počítači.
HummingBoard je dostupný ve třech základních verzích, které se liší především výpočetním výkonem a použitou výbavou.

Youtube: https://www.youtube.com/watch?v=dnGiYir07as#action=share
6. cvičení
Porovnejte výpočetní výkon procesoru ARM a procesoru ve stolním počítači. Proveďte překlad a spuštění některé z vhodných úloh z předchozích cvičení a porovnejte délku výpočtu na obou procesorech pro různou výpočetní složitost. Výsledky zapište do tabulky.
7. přednáška - Procesory ARM a sběrnice SPI, I²C, UART a další
Každý pokročilý procesor je vybaven několika sběrnicemi. Mezi ty známé patří například USB a sériový port. Existují ale také rozhraní, která nejsou běžné známá ale přesto se v hojné míře používají. Patří mezi ně například rozhraní I2C a SPI.
SPI (Serial Peripheral Interface)
Toto rozhraní je velmi pěkně popsáno na české wikipedii. https://cs.wikipedia.org/wiki/Serial_Peripheral_Interface
I²C (Inter-Integrated Circuit)
Opět si dovolím pouze odkázat na wikipedii. https://cs.wikipedia.org/wiki/I%C2%B2C
UART (Universal Asynchronous Receiver and Transmitter)
Jedná se defakto o klasický sériový port, který znáte ze starších počítačů. Rozhraní je často rozšíženo i o možnost synchronní komunikace a pak se oznašuje USART. Popis rozhraní je k dispozici zde: https://en.wikipedia.org/wiki/Universal_asynchronous_receiver/transmitter
GPIO (general purpose input/output)
Toto rozhraní je defakto obdoba paralelního portu a starších počítačů. Jedná se tedy o jednotlivé piny, které jsou přivedeny přímo do procesoru a programátor může v programu ovlivňovat logické napěťové úrovně na těchto pinech.
7. cvičení
K jednodeskovým počítačům je připojen modul Sense HAT. Stručný popis modulu je k dispozici zde: https://pinout.xyz/pinout/sense_hat .
Jelikož je modul připojen k HummingBordu a né k Raspberry-PI, jsou jeho čidla k dispozici na sběrnici /dev/i2c-2. Což je rozdílné oproti Raspberry-Pi.
Příklad knihovny pro práci s obvodem LPS25H je například zde: https://github.com/jbroutier/LPS25H-driver.
Pro použití v prostředí hummingboardu musíte knihovnu i patřičně upravit. Viz přednáška.
extern "C" {
#include <linux/i2c.h>
#include <linux/i2c-dev.h>
#include <i2c/smbus.h>
}
Na webu ale najdete mnohi jiných projektů.
Práce se sběrnicí I2C.
Pro základní práci se sběrnicí I2C v jazyce CPC++ jsou zapotřebí následující úkony:
Přidání hlavičky knihovny
#include <linux/i2c-dev.h>
Otevření souboru reprezentujícího sběrnici i2c
const char *filename = "/dev/i2c-2";
if ((file = open(filename, O_RDWR)) < 0) {
/* ERROR HANDLING: you can check errno to see what went wrong */
perror("Failed to open the i2c bus");
exit(1);
}
Navázání spojení s konkrétním obvodem definovaným adresou
int addr = 0x46; // The I2C address
if (ioctl(file, I2C_SLAVE, addr) < 0) {
printf("Failed to acquire bus access and/or talk to slave.\n");
/* ERROR HANDLING; you can check errno to see what went wrong */
exit(1);
}
Poté již stačí využívat klasických funkcí read() a write() pro čtení a zápis na sběrnici.
if (write(file,pixels,sizeof(pixels)) != sizeof(pixels) ) {
printf("Failed to write to the i2c bus.\n");
exit(1);
}
Ovládání matice RGB led na desce Sense-Hat
Matice led má na sběrnici I2C adresu 0x46.
Pro ovládání jednotlivých LED doporučuji vytvořit následující pole. Jednotlivé prvky v poli odpovídají barvám jednotlivých LED. maximální jas odpovídá hodnotě 0x1F a minimální jas hodnotě 0x0.
uint8_t pixels[] = {
0x00,
0x1F, 0x1F, 0x1F, 0x1F, 0x14, 0x03, 0x00, 0x00, // červené led |
0x00, 0x00, 0x03, 0x12, 0x1F, 0x1F, 0x1F, 0x1F, // zelené led | první řada LED
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x07, // modré led |
0x1F, 0x1F, 0x1F, 0x12, 0x03, 0x00, 0x00, 0x00,
0x00, 0x04, 0x14, 0x1F, 0x1F, 0x1F, 0x1F, 0x1F, // ...
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x08, 0x1D,
0x1F, 0x1F, 0x11, 0x02, 0x00, 0x00, 0x00, 0x00,
0x05, 0x15, 0x1F, 0x1F, 0x1F, 0x1F, 0x1F, 0x0B, // ...
0x00, 0x00, 0x00, 0x00, 0x00, 0x09, 0x1F, 0x1F,
0x1F, 0x0F, 0x02, 0x00, 0x00, 0x00, 0x00, 0x00,
0x17, 0x1F, 0x1F, 0x1F, 0x1F, 0x1F, 0x0A, 0x00, // ...
0x00, 0x00, 0x00, 0x00, 0x0A, 0x1F, 0x1F, 0x1F,
0x0E, 0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x03,
0x1F, 0x1F, 0x1F, 0x1F, 0x1D, 0x08, 0x00, 0x00, // ...
0x00, 0x00, 0x01, 0x0B, 0x1F, 0x1F, 0x1F, 0x1F,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x03, 0x14,
0x1F, 0x1F, 0x1F, 0x1B, 0x07, 0x00, 0x00, 0x00, // ...
0x00, 0x01, 0x0C, 0x1F, 0x1F, 0x1F, 0x1F, 0x1F,
0x00, 0x00, 0x00, 0x00, 0x00, 0x04, 0x15, 0x1F,
0x1F, 0x1F, 0x19, 0x06, 0x00, 0x00, 0x00, 0x00, // ...
0x02, 0x0E, 0x1F, 0x1F, 0x1F, 0x1F, 0x1F, 0x12,
0x00, 0x00, 0x00, 0x00, 0x05, 0x17, 0x1F, 0x1F, // červené led |
0x1F, 0x17, 0x05, 0x00, 0x00, 0x00, 0x00, 0x00, // zelené led | poslední řada LED
0x0F, 0x1F, 0x1F, 0x1F, 0x1F, 0x1F, 0x0F, 0x02, // modré led |
};
Úkol
Vytvořte program pro příkazový řádek, který na LED displayi vytvoří efekt posunujícího se textu. Text bude do programu zadán jako parametr. Jako vzor můžete použít tento program: http://seidl.cs.vsb.cz/download/fonts.tar
Příklady
Program pro zpětné získání písmena z hash Převzato z https://github.com/pod32g/MD5/blob/master/md5.c
/*
* Simple MD5 implementation
*
* Compile with: gcc -o md5 md5.c
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
// Constants are the integer part of the sines of integers (in radians) * 2^32.
const uint32_t k[64] = {
0xd76aa478, 0xe8c7b756, 0x242070db, 0xc1bdceee ,
0xf57c0faf, 0x4787c62a, 0xa8304613, 0xfd469501 ,
0x698098d8, 0x8b44f7af, 0xffff5bb1, 0x895cd7be ,
0x6b901122, 0xfd987193, 0xa679438e, 0x49b40821 ,
0xf61e2562, 0xc040b340, 0x265e5a51, 0xe9b6c7aa ,
0xd62f105d, 0x02441453, 0xd8a1e681, 0xe7d3fbc8 ,
0x21e1cde6, 0xc33707d6, 0xf4d50d87, 0x455a14ed ,
0xa9e3e905, 0xfcefa3f8, 0x676f02d9, 0x8d2a4c8a ,
0xfffa3942, 0x8771f681, 0x6d9d6122, 0xfde5380c ,
0xa4beea44, 0x4bdecfa9, 0xf6bb4b60, 0xbebfbc70 ,
0x289b7ec6, 0xeaa127fa, 0xd4ef3085, 0x04881d05 ,
0xd9d4d039, 0xe6db99e5, 0x1fa27cf8, 0xc4ac5665 ,
0xf4292244, 0x432aff97, 0xab9423a7, 0xfc93a039 ,
0x655b59c3, 0x8f0ccc92, 0xffeff47d, 0x85845dd1 ,
0x6fa87e4f, 0xfe2ce6e0, 0xa3014314, 0x4e0811a1 ,
0xf7537e82, 0xbd3af235, 0x2ad7d2bb, 0xeb86d391 };
// r specifies the per-round shift amounts
const uint32_t r[] = {7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22, 7, 12, 17, 22,
5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20, 5, 9, 14, 20,
4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23, 4, 11, 16, 23,
6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21, 6, 10, 15, 21};
// leftrotate function definition
#define LEFTROTATE(x, c) (((x) << (c)) | ((x) >> (32 - (c))))
void to_bytes(uint32_t val, uint8_t *bytes)
{
bytes[0] = (uint8_t) val;
bytes[1] = (uint8_t) (val >> 8);
bytes[2] = (uint8_t) (val >> 16);
bytes[3] = (uint8_t) (val >> 24);
}
uint32_t to_int32(const uint8_t *bytes)
{
return (uint32_t) bytes[0]
| ((uint32_t) bytes[1] << 8)
| ((uint32_t) bytes[2] << 16)
| ((uint32_t) bytes[3] << 24);
}
void md5(const uint8_t *initial_msg, size_t initial_len, uint8_t *digest) {
// These vars will contain the hash
uint32_t h0, h1, h2, h3;
// Message (to prepare)
uint8_t *msg = NULL;
size_t new_len, offset;
uint32_t w[16];
uint32_t a, b, c, d, i, f, g, temp;
// Initialize variables - simple count in nibbles:
h0 = 0x67452301;
h1 = 0xefcdab89;
h2 = 0x98badcfe;
h3 = 0x10325476;
//Pre-processing:
//append "1" bit to message
//append "0" bits until message length in bits ≡ 448 (mod 512)
//append length mod (2^64) to message
for (new_len = initial_len + 1; new_len % (512/8) != 448/8; new_len++)
;
msg = (uint8_t*)malloc(new_len + 8);
memcpy(msg, initial_msg, initial_len);
msg[initial_len] = 0x80; // append the "1" bit; most significant bit is "first"
for (offset = initial_len + 1; offset < new_len; offset++)
msg[offset] = 0; // append "0" bits
// append the len in bits at the end of the buffer.
to_bytes(initial_len*8, msg + new_len);
// initial_len>>29 == initial_len*8>>32, but avoids overflow.
to_bytes(initial_len>>29, msg + new_len + 4);
// Process the message in successive 512-bit chunks:
//for each 512-bit chunk of message:
for(offset=0; offset<new_len; offset += (512/8)) {
// break chunk into sixteen 32-bit words w[j], 0 ≤ j ≤ 15
for (i = 0; i < 16; i++)
w[i] = to_int32(msg + offset + i*4);
// Initialize hash value for this chunk:
a = h0;
b = h1;
c = h2;
d = h3;
// Main loop:
for(i = 0; i<64; i++) {
if (i < 16) {
f = (b & c) | ((~b) & d);
g = i;
} else if (i < 32) {
f = (d & b) | ((~d) & c);
g = (5*i + 1) % 16;
} else if (i < 48) {
f = b ^ c ^ d;
g = (3*i + 5) % 16;
} else {
f = c ^ (b | (~d));
g = (7*i) % 16;
}
temp = d;
d = c;
c = b;
b = b + LEFTROTATE((a + f + k[i] + w[g]), r[i]);
a = temp;
}
// Add this chunk's hash to result so far:
h0 += a;
h1 += b;
h2 += c;
h3 += d;
}
// cleanup
free(msg);
//var char digest[16] := h0 append h1 append h2 append h3 //(Output is in little-endian)
to_bytes(h0, digest);
to_bytes(h1, digest + 4);
to_bytes(h2, digest + 8);
to_bytes(h3, digest + 12);
}
int main(int argc, char **argv) {
char *msg;
size_t len;
int i;
uint8_t result[16];
if (argc < 2) {
printf("usage: %s 'string'\n", argv[0]);
return 1;
}
msg = argv[1];
len = strlen(msg);
// benchmark
for (i = 0; i < 1000000; i++) {
md5((uint8_t*)msg, len, result);
}
// display result
for (i = 0; i < 16; i++)
printf("%2.2x", result[i]);
puts("");
return 0;
}
Příklad programu se sockety
Problematika soketů je velmi dobře zpracována na různých serverech na internetu, případně by měla být velmi dobře pochopitelná z příkladů dostupných k tomuto předmětu na stránkách Petra Olivky.
Základní úkony při vytváření serveru
//vytvoření socketu int sock_listen = socket( AF_INET, SOCK_STREAM, 0 );
//vytvoření a naplnění struktury in_addr addr_any = { INADDR_ANY }; sockaddr_in srv_addr; srv_addr.sin_family = AF_INET; srv_addr.sin_port = htons( 4444 ); srv_addr.sin_addr = addr_any;
//nastavíme případné vlastnosti socketu setsockopt( sock_listen, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof( opt ) ); //svážeme strukturu se socketem bind( sock_listen, (const sockaddr * ) &srv_addr, sizeof( srv_addr ) ); //začneme naslouchat na daném portu listen( sock_listen, 1 );
//proměnná pro vlastnosti příchozích socketů sockaddr_in rsa; int rsa_size = sizeof( rsa );
//accept je blokující funkce, zde se program zastaví a rozběhne se až po navázání spojení //po navázání spojení se vytvoří nový socket na kterém se již komunikuje s klientem int sock_client = accept( sock_listen, ( sockaddr * ) &rsa, ( socklen_t * ) &rsa_size );
//často se zde použije fork() a vytvoří se pro nově vzniklé spojení nový potomek, který bude obsluhovat klienta //rodičovský proces se pak zpět vrátí na accept a bude očekávat další spojení
Základní úkony při vytváření klienta
// vytvoření socketu int sock_server = socket( AF_INET, SOCK_STREAM, 0 );
// překlad doménových jmen na IP adresu hostent *hostip = gethostbyname( host );
//struktura s vlastnostmi socketu sockaddr_in cl_addr; cl_addr.sin_family = AF_INET; cl_addr.sin_port = htons( port ); cl_addr.sin_addr = * (in_addr * ) hostip->h_addr_list[ 0 ];
//navázání spojení se servererm connect( sock_server, ( sockaddr * ) &cl_addr, sizeof( cl_addr ) )